yolov3论文详解--我们究竟在训练什么
条评论就在写这篇文章的时候,yolo作者Joseph Redmon宣布停止CV研究,很可能yolov3将成为yolo系列的终局。想到这个感觉还是要好好写一下yolo啊。本来只想写一篇来介绍一下yolov3并记录下我是如何用到自己数据集上,写完后发现篇幅很长,遂拆成两部分。
此篇为理论部分,实战部分见http://blog.throneclay.top/2020/03/05/yolo-learning2/。
因为工作原因,需要找一个准确率还不错,而且推理速度较低的网络完成目标检测的能力,马上就想起来yolov3了。说来惭愧的是yolov3出来已经有些时间了,但却一直没有认真阅读。趁这次机会,翻出存放已久的yolo的论文,结合生成的自己的数据好好实践了一把。darknet的这个backbone效果还是非常好的,而且很快我就得到了想要的模型。
模型及实现
模型思想
yolo的核心思想是将物体检测问题转化成回归问题进行求解。最终的输出通过使用不同channel来进行区分,不同channel的信息经过特定的处理得到的物体位置,类别等信息。由于不需要proposal过程对候选框进行计算,yolo的速度可以说是非常快的,而且全网络都是由convolution操作构成,计算效率很高,对于图像尺寸的兼容性非常好。
yolov3的基本思想跟v2保持一致,依旧还是将图像分成若干cell,如果目标的中心点位于此cell中,那么这个cell负责输出目标的各个属性(包括中心点位置,宽度和高度,confidence以及type信息)。
这里说一个cell指的是输入图片的划分,前面的cell随着网络计算产生的下采样效果就变成了一个值。也就是说输出的尺寸大小就代表了输入图像究竟划分成多少cell。
yolov3有三组不同的cell划分。分别是13x13, 26x26和52x52。cell越多说明划分的越细,对于小物体的识别就越好。
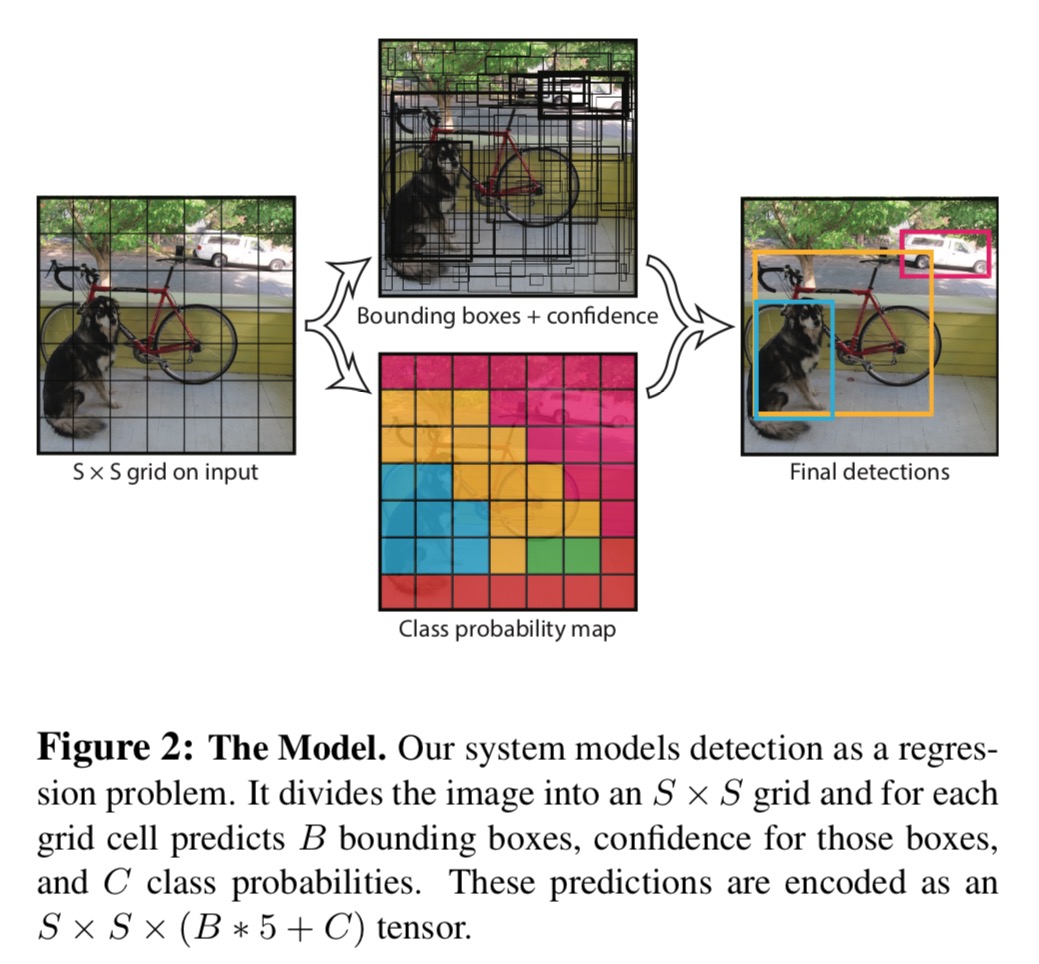
模型结构及yolov3网络结构图
模型结构按照backbone和head来说,backbone就是特征提取网络,head部分就是针对检测的部分网络。 存了一下网络结构,结构太长就不直接展示了,感兴趣的可以看一下yolov3结构图
{kind=link}
backbone
backbone是用的自己设计的darknet网络。在yolov2的时候使用的是darknet19,而在yolov3的时候已经升级到darknet53了(有53层convolution)。
backbone评估的方法基本还是看对分类问题的准确性来确定的。结果就不贴了,作者展示的效果上darknet-53的效果同resnet-152大致相同,但速度快了一倍。其实darknet-53已经采用了类似resnet的结构,随着residual结构的引入,训练效果得到了很大的提升。

head
head部分采用回归的方法直接得出物体的位置和尺寸。计算的层也直接使用了convolution层来进行计算,简单粗暴效果还很好。
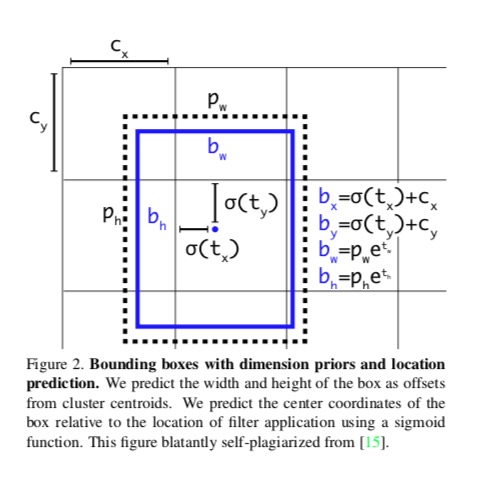
head中score的计算没有使用softmax,而是用的sigmoid,提供了一个cell同时给出多种类别的可能。三组的最后一层都是conv,其H,W就是cell的编号,channel方向上给出希望得到的数据。具体如下
总结
yolov3通过设计3组不同尺寸的anchor来增强对小物体的检测,用更鲁棒的backbone来升级特征提取。整体思路非常清晰,论文写的偏口语化,阅读起来难度不大。写完发现还有很多地方可以展开介绍,后面会不定期更新。
本文标题:yolov3论文详解--我们究竟在训练什么
文章作者:throneclay
发布时间:2020-02-19
最后更新:2022-08-03
原始链接:http://blog.throneclay.top/2020/02/19/yolo-learning/
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!