Intel OpenMP的线程亲和度
条评论最近在看一本书,又提到了OpenMP的线程亲和度问题,结合以前的知识,在这里就整理一下,方便以后查阅.
线程亲和度是OpenMP开线程后,各个线程跟CPU核的关系的一个概念. 有时候调整一下线程亲和度,对于程序性能可能会有意想不到的收获.
Intel OpenMP的runtime library能够实现对OpenMP线程和物理核的绑定,本文中OpenMP是用的Intel OpenMP library.
设置方式
使用 KMP_AFFINITY 环境变量
语法:1
setenv KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>]
使用intel compiler的参数 -par-affinity选项
语法:1
-par-affinity=[<modifier>,...]<type>[,<permute>][,<offset>]
修改OpenMP缺省方式
语法:1
kmp_set_defaults("setenv KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>]")
将上一句话放在开多线程前,也可以起到修改线程亲和度的效果.这种方法实质是修改了OpenMP在找不到相关环境变量时,缺省的状态.当你定义过环境变量或者使用编译参数后,这种方法就没有效果了.这些方法都属于high-level affinity interface,使用环境变量来控制线程与处理器的关系.除了这些方法,还有low-level affinity interface, 通过使用API来调用runtime library将线程绑定在特定的处理器上运行.
参数的取值
type的取值
type 的取值可以是以下几种:
none
compact
disabled
explicit
scatter
logical
physical
type = none(default)
不将线程绑定到特定处理器,使用操作系统调度,可以用环境变量KMP_AFFINITY=verbose,none来看看系统是如何映射的.
type = compact
就如compact的意思一样,线程会先充分利用第一个核,当第一个核上所有硬件线程都被分配后,再充分分配到第二个核,依次类推下去.例如有6核12线程的处理器,分配7个线程,前3个核各获得2个线程,最后一个线程被分配到第四个核,最后两个核没有用到.给一张Intel给的图例:
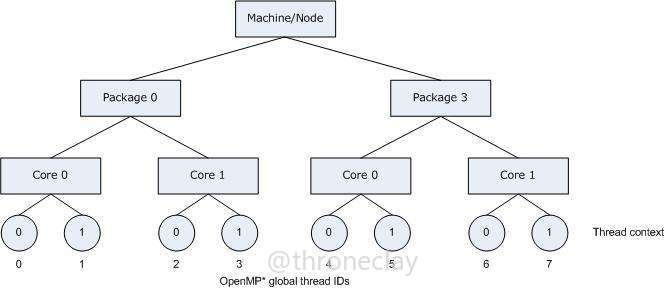
Intel给的图例给出了完整的映射逻辑,在内部映射时, 就是采用这种方式,compact方式会得到这样的一棵树, 递归填满左子树,直到所有线程分配完毕.图中package是封装的意思,就是你有几个独立的CPU.
type = disabled
设置为disable将禁用thread affinity接口,OpenMP的runtime library将接受操作系统调度.注意,此时disable会应用在runtime library上,也就是说low-level affinity interface 也将被禁用,如 kmp_set_affinity(), kmp_get_affinity, 如果调用他们将会返回不为零的值.
type = explicit
明确每个线程同每个核的绑定,这时需要一个proclist=[….]的参数来告知线程绑定到哪些核上.绑定后,在生存期内线程不会再被调度到其他核.
type = scatter
采用scatter方式,线程会被尽可能平均分配.例如一个6核12线程的处理器,分配7个线程, 6个核上先各获得一个线程,再把最后一个线程分配给第一个核.Intel给的图例:
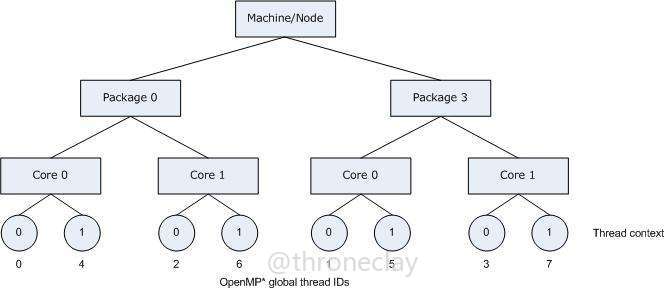
logical 和 physical不建议使用,因为以后intel Compiler可能会不再支持这两种方式,他们其实类似与compact和scatter方式,这里就不再多说了。
modifier的取值
取值可以是以下几种:
noverbose
norespect
nowarnings
granularity=< specifier >
proclist={ }
respect
verbose
warnings
缺省值为noverbose respect warnings granularity=core
verbose 和 noverbose指输出详细信息,可以用verbose看一下当前的映射关系. respct和norespct 指的是否遵从处理器的affinity mask,不同操作系统值不一定一样. warnings和nowarnings指是否输出警告. proclist={ }指的是绑定到的处理器的procs id,当type=explicit时可用.
granularity=
至于low-level affinity interface还是不建议使用,因为使用后,可能换其他的CPU运行会出现很多问题,降低代码移植性,这里也就不再多说了,如果特殊需求,可以参考intel compiler 用户手册.
在我们服务器上测试一个OpenMP的代码, 使用 KMP_AFFINITY = verbose,compact方式输出的结果,从第6行可以看到有2个package说明是双路CPU, 每个CPU有六个核,每个核有2个硬件线程. 映射是从0号开始,一直到23号,分别分配给了0-23号OS procs.
1 | OMP: Info #204: KMP_AFFINITY: decoding x2APIC ids. |
参考文献:
- User and Reference Guide for the Intel C++ Compiler 15.0
- Using Intel OpenMP Thread Affinity for Pinning: http://www.nas.nasa.gov/hecc/support/kb/using-intel-openmp-thread-affinity-for-pinning_285.html
本文标题:Intel OpenMP的线程亲和度
文章作者:throneclay
发布时间:2015-10-09
最后更新:2022-08-03
原始链接:http://blog.throneclay.top/2015/10/09/intelOpenmp/
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!