Intel KNL的特点及功能介绍
条评论Intel KNL是Intel MIC架构的第二代产品代号,其一代产品为KNC。新的产品从计算能力到访存性能都较上一代有了明显提升,灵活的启动和模式设置增加了其对高性能应用的适应性。KNL之前被寄予厚望,我们实验室一直迫不及待的想拿来试一试。Intel KNL直到16年7月份才陆续拿到机器,资料比较有限,这里记录了二代MIC的新的特点及一些重要功能介绍,方便以后回顾和查阅。
概述
先说一下命名规则,第一代的Xeon Phi的编号是3110,5110,7110,7120,因此也被称为X100,而第二代为了跟一代区别,同时为了能有点共性,就被称为X200,我们拿到的是7210,实际上还是7230,7250,7290,其中,7290是最高配版,核数最多(72核),频率最高。
二代MIC最大的特点就是直插主板,直插主板的型号有两种,一种不带fabric,另一种带fabric(命名后面带F如7210F),另外还提供有PCIE版,目前还没出来,型号暂时未知。
给张图可能会更清楚,这是在KNL的一般介绍中都有的图,KNL封装有16G的MCDRAM,速度较快,在400GB/s左右。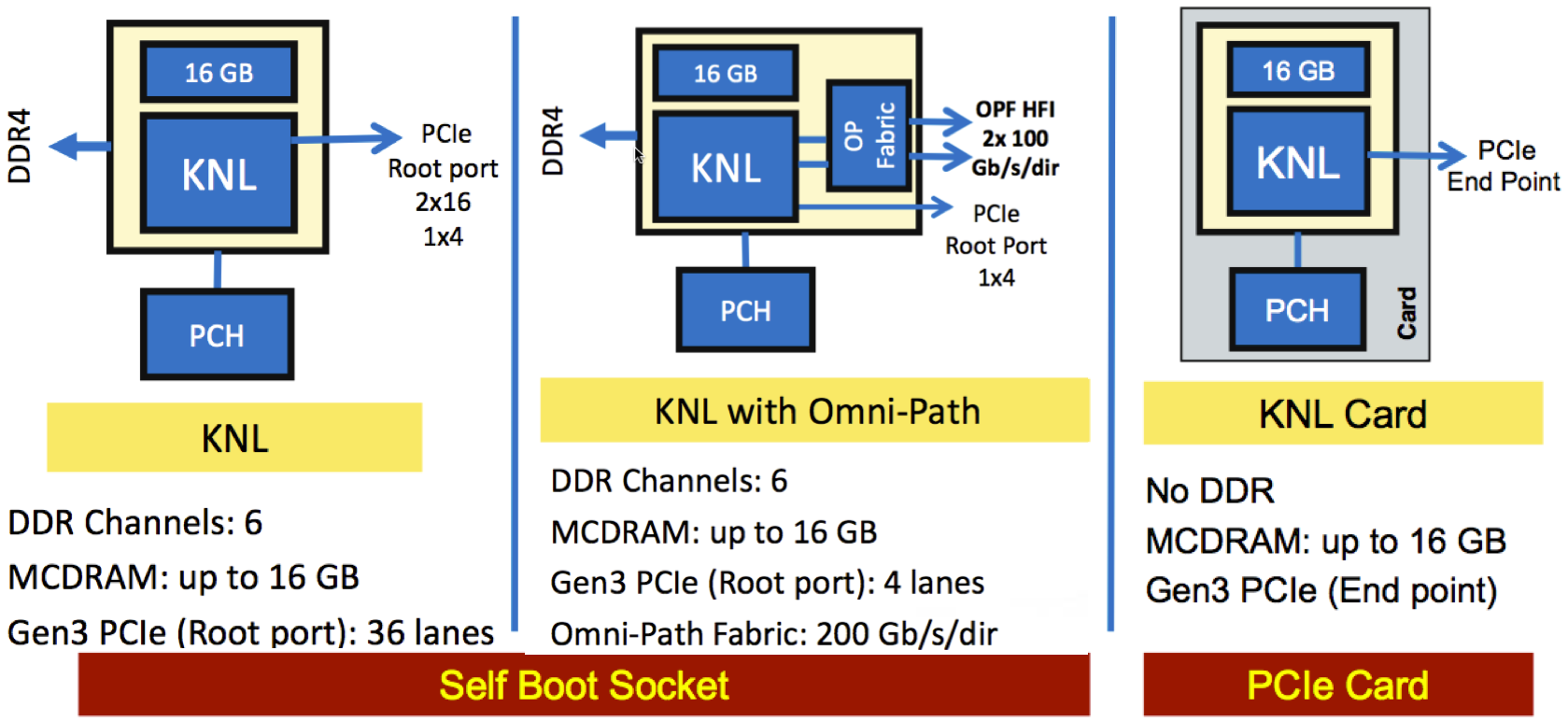
Microarchitecture
一个细节图把参数基本说的很详细了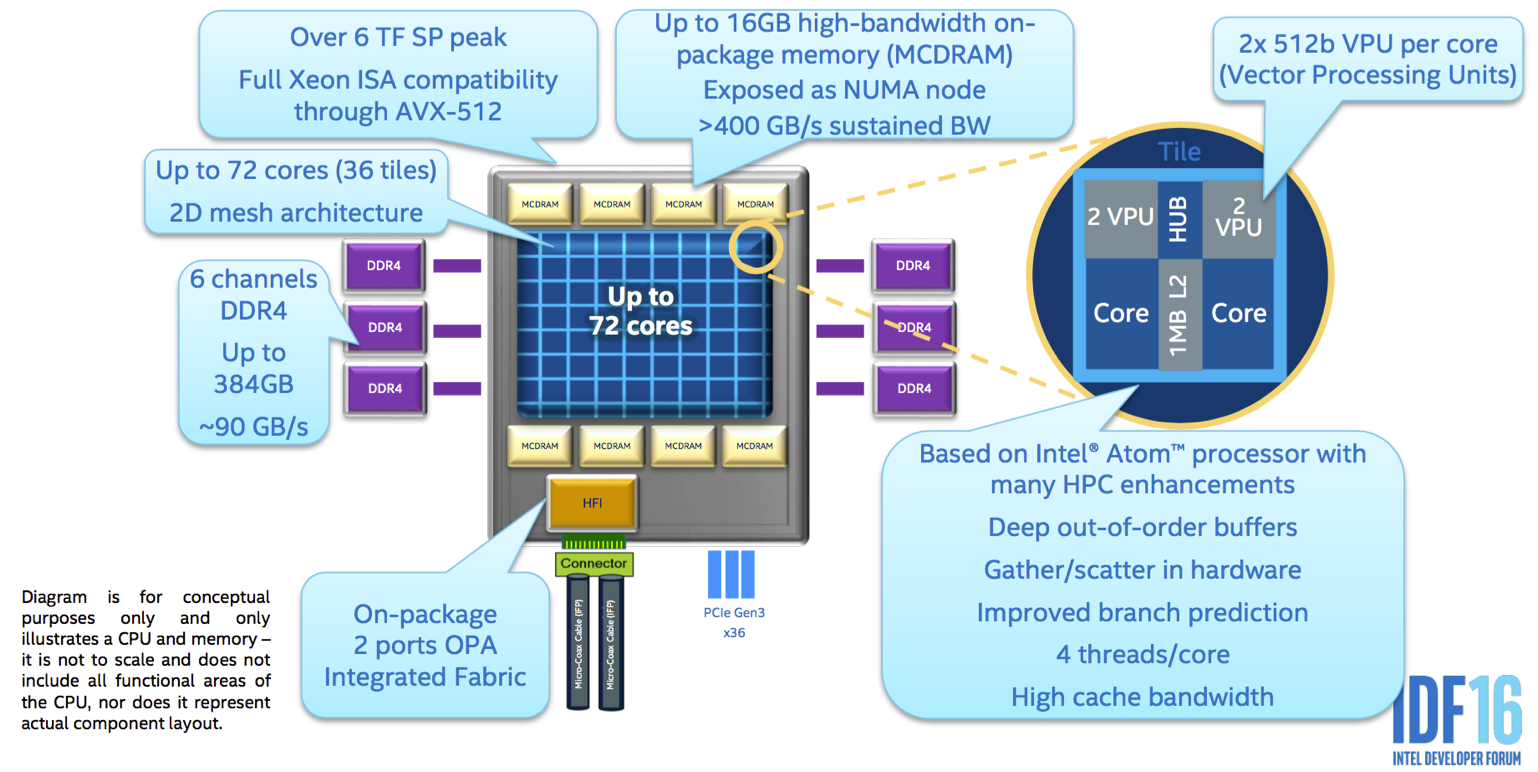
Key Features
二代同一代最大的提升主要有这么7个方面:
- 自启动的Processor,没有PCIE的瓶颈
- 同Xeon的某些型号二进制兼容,legacy汇编的代码不需要重新编译,可以直接拿过来使用
- 72个核,每个核心都是基于silvermont架构(atom的一代产品),带来了3倍的单核性能提升。
- AVX512, 采用了新的AVX512向量化指令,宽度虽然同上一代一致,但指令更加完善。
- Scatter/Gather指令的硬件支持
- MCDRAM和ddr4的支持,片上的16GB MCDRAM可以配置成多种模式,大大提高了KNL的灵活程度,方便不同的算法特点。
- 新的2D-mesh连接片上多核,第一代采用的是所有的核都挂在同一个ring上,这一代采用了2D-mesh连接多个tile,每个tile有两个核心,每个核心又有4个硬件线程和2个VPU。
Cluster Modes
Cluster模式大的方面分为五种模式,但中间有几种结构很相似,因此一般介绍的时候都分为三种模式,分别为AlltoAll模式,Hemisphere/Quadrant模式和SNC2/SNC4模式。这几种模式对计算的影响不大,但会显著影响你的Cache性能,从而影响程序的整体计算性能。有个网站已经很好的做了介绍了https://colfaxresearch.com/knl-numa/,这里简单记录下:
一代和二代MIC都采用DTD(Distributed Tag Directory)来控制缓存一致性问题,对于一代产品,所有的核心都挂在一个打的Ring上,当一个核心发生cache miss问题时,会通过Ring来查看是否这个memory被其他核心cache过,也就是一个Ring挂着61个核心,效率较低。二代产品两个核心为一个Tile,通过控制Tile和Memory以及MCDRAM控制器的绑定来加速查找cache过程,发生Cache miss后也能以较低开销完成操作。二代MIC的Cluster连接采用2D mesh,每次会沿着Y向和X向分别进行数据传输,即在Mesh中,任意Tile能两次数据传输内找到其他的任意一个Tile。
为了更好的解释他的工作原理,这里对几种Cache miss进行分别介绍,假设A为发生Cache miss的Tile,而B为可能已缓存过这个Memory的Tile,D为Memory 控制器。
AlltoAll 模式
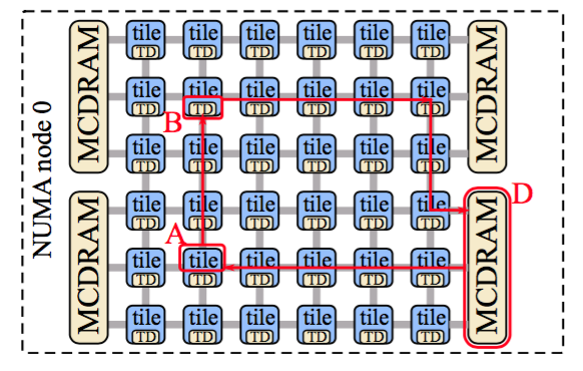
这种模式下所有的Tile全连接,Tile和MCDRAM控制器之间不会绑定,内存地址均分到所有的TD(Tag Directory)上。
cache miss的四种情况:
- L1 hit:直接返回。
- L2 hit:由于每个核心都具有各自的L1,每个Tile共享一个L2 cache,发生L1 miss后会去直接查看L2 cache。
- L2 miss,Tile B hit:如果L2 miss后,Tile A会询问DTD,DTD hash到Tile B可能会有,Tile B可能会在任何位置,但仍然能够两次内完成访问。然后Tile A会找到这个Tile B,拿到Cache。
- Tile B miss:Tile B会找到这个memory对应的memory 控制器D,由于地址可能会在任何地方,一种可能的D的位置如图,此时完成访存,完成整个过程。
这4种过程中,第四种情况的发生很可能会严重影响性能,接下来的模式可以改善这种情况发生对性能的影响。
Hemisphere/Quadrant 模式
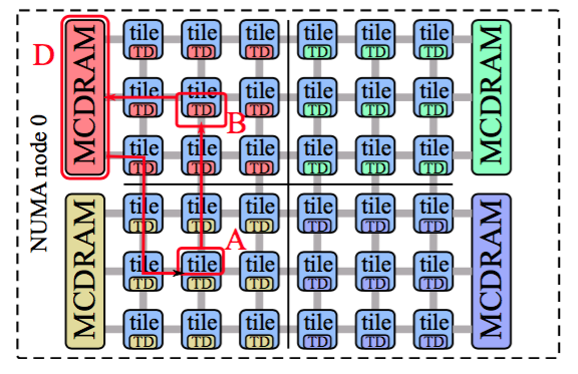
在这种模式下,所有核心被分为2部分(Hemisphere)或4部分(Quadrant),memory 控制器所负责的地址会被固定到对应的划分区域。以Quadrant模式为例,其前3种情况同AlltoAll模式,只有第四种情况会得到提升。
cache miss的四种情况:
- L1 hit:直接返回。
- L2 hit:由于每个核心都具有各自的L1,每个Tile共享一个L2 cache,发生L1 miss后会去直接查看L2 cache。
- L2 miss,Tile B hit:如果L2 miss后,Tile A会询问DTD,DTD hash到Tile B可能会有,Tile B可能会在任何位置,但仍然能够两次内完成访问。然后Tile A会找到这个Tile B,拿到Cache。
- Tile B miss:Tile B会找到这个memory对应的memory 控制器D,地址此时同Tile B分在同一侧,所以能够迅速找到MCDRAM控制器,完成访存,完成整个过程。
SNC2/SNC4 模式
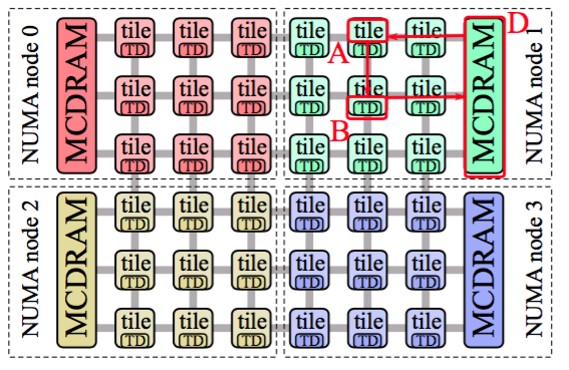
这种sub-NUMA的模式会把整个核心划分为2个(SNC2)或4个(SNC4)NUMA节点。对于有NUMA-aware的软件,这种设置的效果会很好。这种情况下,如果一个NUMA节点访问另一个NUMA节点的memory性能会很差,甚至可能出错。使用MPI加OpenMP的并行编程方法能够较好的完成此模式的并行。
cache miss的四种情况:
- L1 hit:直接返回。
- L2 hit:由于每个核心都具有各自的L1,每个Tile共享一个L2 cache,发生L1 miss后会去直接查看L2 cache。
- L2 miss,Tile B hit:如果L2 miss后,Tile A会询问DTD,DTD hash到Tile B可能会有,Tile B在同NUMA节点内。然后Tile A会找到这个Tile B,拿到Cache。
- Tile B miss:Tile B会找到这个memory对应的memory 控制器D,地址此时同Tile B分在同一侧,所以能够迅速找到MCDRAM控制器,完成访存,完成整个过程。
如何设置Cluster Modes
KNL的Cluster Mode设置必须通过BIOS来进行。
- 进入BIOS(开机按DEL键)
- 选择chipset configuration
- 选择north bridge
- 选择uncore configuration
- 进入cluster mode,就可以设置模式了。
Memory Modes
Intel KNL共有三种Memory模式,分别是Flat模式,Cache模式和Hybrid模式。他们的区别用下面一张图片来表示
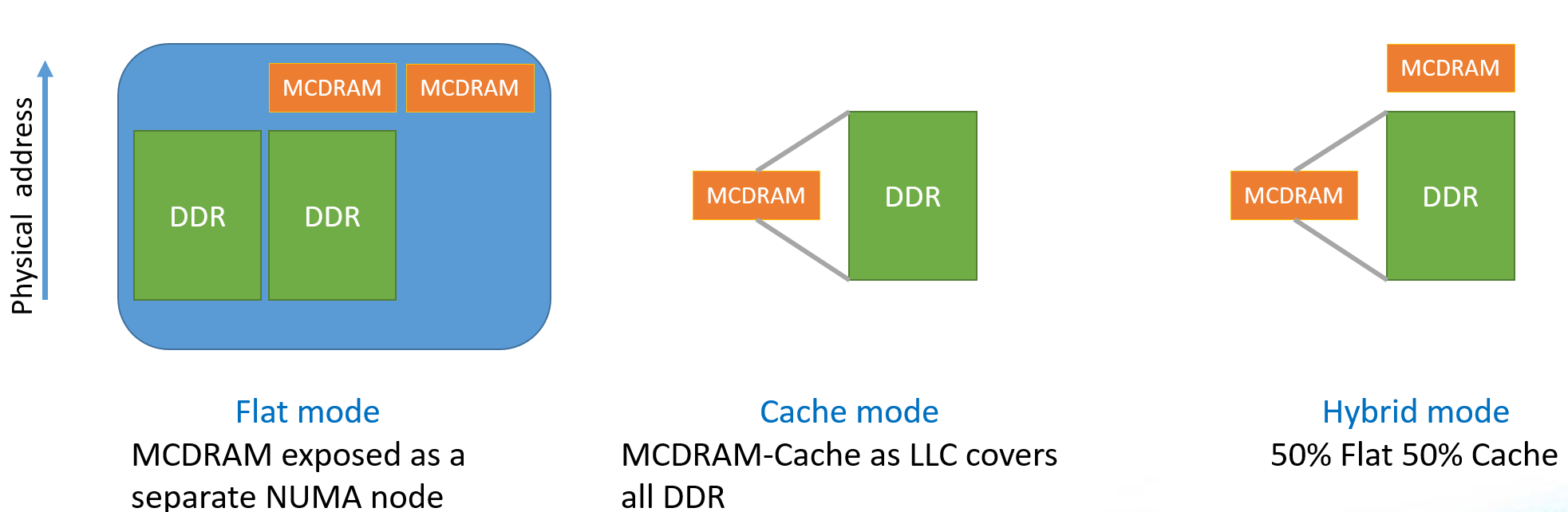
三种模式最大的区别就是在于片上个的MCDRAM对程序员是否可见,Flat模式下完全可见,Cache模式下完全不可见,Hybrid模式下部分可见。
Flat模式下,能够让用户控制MCDRAM,需要编程的支持,需要用专门的malloc方法来访问(hbwmalloc)。当程序需要的代码较大时,可以人工控制MCDRAM内的数据,比较方便。
Cache模式:用户不需要任何额外修改代码的地方,当程序占用的内存较小时,这种模式能够自动的将代码需要的内存全部Cache住,无需代码修改就能体验到MCDRAM带来的加速效果,缺点是当代码需要内存较大时,如果MCDRAM的Cache发生了Cache miss,这个查询Cache的路径会变得很长,可能导致较差的访存性能。
Hybrid模式:兼具Flat模式和Cache模式的特点,能用的MCDRAM较小,Cache的尺寸也较小,如果用不好,会将两者的缺点集中起来,一般不建议使用。
如何设置Memory Modes
KNL的Memory Mode设置也必须通过BIOS来进行。
- 进入BIOS(开机按DEL键)
- 选择chipset configurationin
- 选择north bridge
- 选择uncore configuration
- 进入memory mode,就可以设置模式了。
如何查看自己的Cluster Mode和Memory Mode
查看自己当前的模式设置,需要用下面一行命令,根据输出来判断就好了。
1 | sudo hwloc-dump-hwdata |
Memkind & hbwmalloc
在MCDRAN上使用和分配内存,建议使用hbwmalloc来操作,这里给出他的部分用法。
1 | HBWMALLOC(3) HBWMALLOC HBWMALLOC(3) |
ISA
使用AVX512需要注意下面几点:
头文件: immintrin.h
对于intel的编译器,使用编译选项: -xMIC-AVX512
对于GCC,使用编译选项: -mavx512f -mavx512cd -mavx512er -mavx512pf
对于指令的接口,需要查看Intel手册。
总结
写这篇博客的时候正值找工作,加上一些乱七八糟的事情,使得这篇博客一直没有完成,现在工作也稍微定了下回过头来赶紧补上。
本文标题:Intel KNL的特点及功能介绍
文章作者:throneclay
发布时间:2016-08-20
最后更新:2022-08-03
原始链接:http://blog.throneclay.top/2016/08/20/knl_mcdram/
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!